SEO优化
SEO优化 谷歌SEO怎样做?和百度SEO有多大区别?本质上差别不大,但有些细节差异。由于谷歌搜索技术的领先,掌握Google SEO十分重要,前几天一位国内某大型电商SEO部门的朋友问我一个很有意思的Google排名问题,一两句话说不清楚,所以写个帖子回答,也许对其它SEO也有帮助。
TDK优化
TDK为title,description,keywords三个的统称。当然title是最有用的,是非常值得优化的;而keywords因为以前被seo人员过度使用,所以现在对这个进行优化对搜索引擎是没用的,这里就不说了;description的描述会直接显示在搜索的介绍中,所以对用户的判断是否点击还是非常有效的。
title优化
title的分隔符一般有,,_,-等,其中_对百度比较友好,而-对谷歌比较友好,第四个为空格,英文站点可以使用,中文少用。title长度一般pc端大概30个中文,移动端20个,超过则会截断为省略号。
因为业务关系,我们做的更多的是针对百度搜索引擎的优化,所以这里把百度搜索引擎优化的建议分享下:
title格式:
- 首页:
网站名称或者网站名称_提供服务介绍or产品介绍 - 频道页:
频道名称_网站名称 - 文章页:
文章title_频道名称_网站名称
如果你的文章标题不是很长,还可以加入点关键词进去,如文章title_关键词_网站名称
推荐做法:
- 每个网页应该有一个独一无二的标题,切忌所有的页面都使用同样的默认标题
- 标题要主题明确,包含这个网页中最重要的内容
- 简明精练,不罗列与网页内容不相关的信息
- 用户浏览通常是从左到右的,重要的内容应该放到title的靠前的位置
- 使用用户所熟知的语言描述。如果你有中、英文两种网站名称,尽量使用用户熟知的那一种做为标题描述
description优化
description不是权值计算的参考因素,这个标签存在与否不影响网页权值,只会用做搜索结果摘要的一个选择目标。其长度pc端大概为78个中文,移动端为50个,超过则会截断为省略号。
百度推荐做法为:
- 网站首页、频道页、产品参数页等没有大段文字可以用做摘要的网页最适合使用description
- 准确的描述网页,不要堆砌关键词
- 为每个网页创建不同的description,避免所有网页都使用同样的描述
- 长度合理,不过长不过短
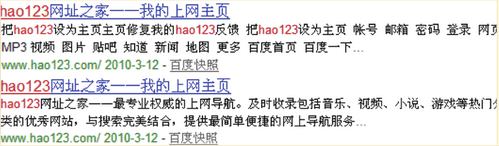
下面以百度推荐的两个例子为对比,第一个没有应用meta description,第二个应用了meta description,可以看出第一个结果的摘要对用户基本没有参考价值,第二个结果的摘要更具可读性,可以让用户更了解网站的内容。
页面内容优化
使用html5结构
如果条件允许(如移动端,兼容ie9+,如果ie8+就针对ie8引入html5.js吧),是时候开始考虑使用html5语义化标签。如header,footer,section,aside,nav,article等,这里我们截图看一个整体布局

唯一的H1标题
每个页面都应该有个唯一的h1标题,但不是每个页面的h1标题都是站点名称。(但html5中h1标题是可以多次出现的,每个具有结构大纲的标签都可以拥有自己独立的h1标题,如header,footer,section,aside,article)
首页的h1标题为站点名称,内页的h1标题为各个内页的标题,如分类页用分类的名字,详细页用详细页标题作为h1标题
<!-- 首页 -->
<h1 class="page-tt">腾讯课堂</h1>
<!-- 分类页 -->
<h1 class="page-tt">前端开发在线培训视频教程</h1>
<!-- 详细页 -->
<h1 class="page-tt">html5+CSS3</h1>
img设置alt属性
img必须设置alt属性,如果宽度和高度固定请同时设置固定的值
nofollow
对不需要跟踪爬行的链接,设置nofollow。可用在博客评论、论坛帖子、社会化网站、留言板等地方,也可用于广告链接,还可用于隐私政策,用户条款,登录等。如下代码表示该链接不需要跟踪爬行,可以阻止蜘蛛爬行及传递权重。
<a href="http://example.com" rel="nofollow">no follow 链接</a>
正文
内容方面考虑:
- 自然写作
- 高质量原创内容
- 吸引阅读的写作手法
- 突出卖点
- 增强信任感
- 引导进一步行为
用户体验方面考虑:
- 排版合理、清晰、美观、字体、背景易于阅读
- 实质内容处在页面最重要位置,用户一眼就能看到
- 实质内容与广告能够清晰区分
- 第一屏就有实质内容,而不是需要下拉页面才能看到
- 广告数量不宜过多,位置不应该妨碍用户阅读
- 如果图片、视频有利于用户理解页面内容,尽量制作图片、视频等
- 避免过多弹窗
URL优化
URL设计原则:
- 越短越好
- 避免太多参数
- 目录层次尽量少
- 文件及目录名具描述性
- URL中包括关键词(中文除外)
- 字母全部小写
- 连词符使用
-而不是_ - 目录形式而非文件形式
URL静态化
以现在搜索引擎的爬行能力是可以不用做静态化的,但是从收录难易度,用户体验及社会化分享,静态简短的URL都是更有利的。
URL静态化还是不静态化?
数据库驱动的网站需要将URL静态化,一直以来都是SEO最基本的要求,可以算是个常识性的东西。现在恐怕也没有不是数据库驱动的网站了吧。
近几年SEO行业一致认为,URL中带2-3个问号不是问题,搜索引擎通常都能收录,尤其是权重高点的域名,更多几个问号也不是问题。但无论如何一般还是建议URL静态化。
2008年9月份,Google站长博客发表了一篇讨论动态网址还是静态网址的帖子,却颠覆了这个说法。在这篇帖子里,Google明确建议不要将动态URL静态化,而是保留那种长长的,带问号参数的动态URL。Google黑板报和中文网站管理员博客都做了翻译和转载,大家可以查看。
从留言和我看到的博客来看,有不少人还真觉得有道理,准备按照Google说的做了。
这是比较少见的,我十分不以为然的,Google给的SEO建议。
Google的帖子有几个要点。
一是Google完全有能力抓取动态网址,多少个问号也不是问题。这一点基本靠谱。但如果URL中出现个十几二十个问号和参数呢?Google会怎样看待?即使有能力抓取,又一定会愿意抓取吗?其它搜索引擎又会怎样处理?
第二,动态网址更有助于Google蜘蛛读懂URL含义,并进行鉴别,因为网址中的参数有提示性。比如Google举了这个例子:
http://www.example.com/article/bin/answer.foo?language=en&answer=3&sid=98971298178906&query=URL
URL里的参数都有助于Google理解URL及网页内容。比如language后面跟的参数是提示语言,answer后面跟的是文章编号,sid后面的肯定是session ID。其他常用的包括color后面跟的参数指的是颜色,size后面跟的参数是尺寸等。有了这些参数的帮助,Google更容易理解网页。
而将网址静态化后,这些参数的意义通常就变得不明显了。比如这个URL:
http://www.example.com/shoes/red/7/12/men/index.html
就可能使Google不知道哪个是产品序列号,哪个是尺寸等。
第三,网址静态化很容易弄错,那就更得不偿失了。比如通常动态网址的参数调换顺序,所得到的页面其实是相同的,比如这两个网址很可能就是同一个页面:
http://www.example.com/article/bin/answer.foo?language=en&answer=3
http://www.example.com/article/bin/answer.foo?answer=3&language=en
保留动态网址,Google还比较容易明白这是一样的网页。而经过静态化后,这样两个网址Google就不容易判断是不是同一个页面,从而可能引起复制内容:
http://www.example.com/shoes/men/7/red/index.html
http://www.example.com/shoes/red/7/men/index.html
再一个容易搞错的是session ID,也可能被静态化进URL:
http://www.example.com/article/bin/answer.foo/en/3/98971298178906/URL
这样网站将产生大量URL不同,但其实内容相同的页面。
所以,Google建议不要静态化URL。
但是我还是建议要静态化。原因是:
首先,Google给的建议是从Google自己出发,而没有考虑其他搜索引擎。Google抓取动态网址没问题,并不意味着雅虎,百度,微软等等就都没问题。尤其是中文网站,Google不是老大。实际上,百度直到现在,2021年,对多个问号的URL还是不太愿意抓取的。
第二,Google所说静态化的坏处,是基于静态化做得不正确的假设上。问题是要做静态化就得做正确,假设会做错是没有什么道理的。有几个人会静态化网址时还把session ID放进去呢?
第三,Google的建议是典型的有利于自己,而不利于用户。带有问号参数的URL可能有助于Google读懂内容,但是显然非常不利于用户在一撇之下理解网站结构及大致内容。看看这两个网址哪个更清晰,更容易读懂,更有可能被点击呢?
http://www.example.com/product/bin/answer.foo?language=en&productID=3&sid=98971298178906&cat=6198&&query=URL
http://www.example.com/product/men/shoes/index.html
显然是第二个。
而且长的动态网址,也不利于记忆,不利于在邮件、社会化网站等地方抄给别人。
总之,虽然Google这么明确的建议保留动态网址,我还是建议正相反,尽量将URL静态化。
URL规范化
1、统一连接
http://www.domainname.com
http://domainname.com
http://www.domainname.com/index.html
http://domainname.com/index.html以上四个其实都是首页,虽然不会给访客造成什么麻烦,但对于搜索引擎来说就是四条网址,并且内容相同,很可能会被误认为是作弊手段,而且当搜索引擎要规范化网址时,需要从这些选择当中挑一个最好的代表,但是挑的这个不一定是你想要的。所以最好自己就规范好。
2、301跳转
第一种是URL发生改变,一定要把旧的地址301指向新的,不然之前做的一些收录权重什么的全白搭了。
第二种是一些cms系统,极有可能会造成多个路径对应同一篇文章。如drupal默认的路径是以node/nid,但是如果启用了path token,就可以自己自定义路径。这样一来就有两条路径对应同一篇文章。所以可以启用301,最终转向一个路径。
3、canonical
这个标签表示页面的唯一性(这个标签以前百度不支持,现在支持),用在平时参数传递的时候,如:
//:ke.qq.com/download/app.html
//:ke.qq.com/download/app.html?from=123
//:ke.qq.com/download/app.html?from=456以上三个表示三个页面,但其实后两个只是想表明从哪来的而已,所以为了确保这三个为同一个页面,我们在head上加上canonical标签。
<link rel="cononical" href="//:ke.qq.com/download/download/app.html" />
robots
robots.txt
搜索引擎蜘蛛访问网站时会第一个访问robots.txt文件,robots.txt用于指导搜索引擎蜘蛛禁止抓取网站某些内容或只允许抓取那些内容,放在站点根目录。
以腾讯课堂的robots.txt为例:
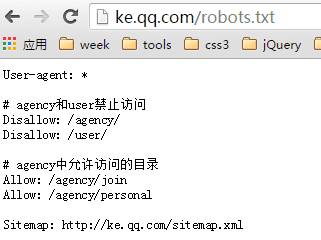
- User-agent 表示以下规则适用哪个蜘蛛,
*表示所有 #表示注释- Disallow 表示禁止抓取的文件或目录,必须每个一行,分开写
- Allow 表示允许抓取的文件或目录,必须每个一行,分开写
- Sitemap 表示站点XML地图,注意S大写
下面表示禁止所有搜索引擎蜘蛛抓取任何内容
User-agent: *
Disallow: /
下面表示允许所有搜索引擎蜘蛛抓取任何内容
User-agent: *
Disallow:
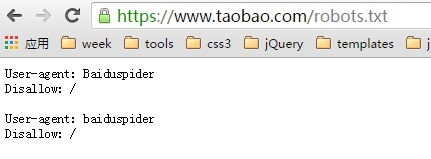
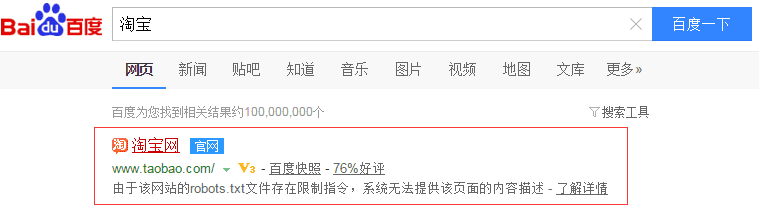
注意:被robots禁止抓取的URL还是肯呢个被索引并出现在搜索结果中的。只要有导入链接指向这个URL,搜索引擎就知道这个URL的存在,虽然不会抓取页面内容,但是索引库还是有这个URL的信息。以淘宝为例:
禁止百度搜索引擎抓取
百度搜索有显示
如何使用robots.txt及其详解
在国内,网站管理者似乎对robots.txt并没有引起多大重视,应一些朋友之请求,今天想通过这篇文章来简单谈一下robots.txt的写作。
robots.txt基本介绍
robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被robots访问的部分,或者指定搜索引擎只收录指定的内容。
当一个搜索机器人(有的叫搜索蜘蛛)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取。
另外,robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。
robots.txt写作语法
首先,我们来看一个robots.txt范例:https://www.example.com/robots.txt
访问以上具体地址,我们可以看到robots.txt的具体内容如下:
# Robots.txt file from https://www.example.com
# All robots will spider the domain
User-agent: *
Disallow:
以上文本表达的意思是允许所有的搜索机器人访问https://uzbox.com站点下的所有文件。
具体语法分析:其中#后面文字为说明信息;User-agent:后面为搜索机器人的名称,后面如果是*,则泛指所有的搜索机器人;Disallow:后面为不允许访问的文件目录。
下面,我将列举一些robots.txt的具体用法:
允许所有的robot访问
User-agent: *
Disallow:
或者也可以建一个空文件 “/robots.txt” file
禁止所有搜索引擎访问网站的任何部分
User-agent: *
Disallow: /
禁止所有搜索引擎访问网站的几个部分(下例中的01、02、03目录)
User-agent: *
Disallow: /01/
Disallow: /02/
Disallow: /03/
禁止某个搜索引擎的访问(下例中的BadBot)
User-agent: BadBot
Disallow: /
只允许某个搜索引擎的访问(下例中的Crawler)
User-agent: Crawler
Disallow:
User-agent: *
Disallow: /
另外,我觉得有必要进行拓展说明,对robots meta进行一些介绍:
Robots META标签则主要是针对一个个具体的页面。和其他的META标签(如使用的语言、页面的描述、关键词等)一样,Robots META标签也是放在页面的<head></head>中,专门用来告诉搜索引擎ROBOTS如何抓取该页的内容。
Robots META标签的写法:
Robots META标签中没有大小写之分,name=”Robots”表示所有的搜索引擎,可以针对某个具体搜索引擎写为name=”BaiduSpider”。 content部分有四个指令选项:index、noindex、follow、nofollow,指令间以“,”分隔。
INDEX 指令告诉搜索机器人抓取该页面;
FOLLOW 指令表示搜索机器人可以沿着该页面上的链接继续抓取下去;
Robots Meta标签的缺省值是INDEX和FOLLOW,只有inktomi除外,对于它,缺省值是INDEX,NOFOLLOW。
这样,一共有四种组合:
<META NAME=”ROBOTS” CONTENT=”INDEX,FOLLOW”>
<META NAME=”ROBOTS” CONTENT=”NOINDEX,FOLLOW”>
<META NAME=”ROBOTS” CONTENT=”INDEX,NOFOLLOW”>
<META NAME=”ROBOTS” CONTENT=”NOINDEX,NOFOLLOW”>其中
<META NAME=”ROBOTS” CONTENT=”INDEX,FOLLOW”>可以写成<META NAME=”ROBOTS” CONTENT=”ALL”>;
<META NAME=”ROBOTS” CONTENT=”NOINDEX,NOFOLLOW”>可以写成<META NAME=”ROBOTS” CONTENT=”NONE”>
目前看来,绝大多数的搜索引擎机器人都遵守robots.txt的规则,而对于Robots META标签,目前支持的并不多,但是正在逐渐增加,如著名搜索引擎GOOGLE就完全支持,而且GOOGLE还增加了一个指令“archive”,可以限制GOOGLE是否保留网页快照。例如:
<META NAME=”googlebot” CONTENT=”index,follow,noarchive”>
表示抓取该站点中页面并沿着页面中链接抓取,但是不在GOOLGE上保留该页面的网页快照。
如何使用robots.txt
robots.txt 文件对抓取网络的搜索引擎漫游器(称为漫游器)进行限制。这些漫游器是自动的,在它们访问网页前会查看是否存在限制其访问特定网页的 robots.txt 文件。如果你想保护网站上的某些内容不被搜索引擎收入的话,robots.txt是一个简单有效的工具。这里简单介绍一下怎么使用它。
如何放置Robots.txt文件
robots.txt自身是一个文本文件。它必须位于域名的根目录中并 被命名为”robots.txt”。位于子目录中的 robots.txt 文件无效,因为漫游器只在域名的根目录中查找此文件。例如,http://www.example.com/robots.txt 是有效位置,http://www.example.com/mysite/robots.txt 则不是。
这里举一个robots.txt的例子:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~name/
使用 robots.txt 文件拦截或删除整个网站
要从搜索引擎中删除您的网站,并防止所有漫游器在以后抓取您的网站,请将以下 robots.txt 文件放入您服务器的根目录:
User-agent: *
Disallow: /
要只从 Google 中删除您的网站,并只是防止 Googlebot 将来抓取您的网站,请将以下 robots.txt 文件放入您服务器的根目录:
User-agent: Googlebot
Disallow: /
每个端口都应有自己的 robots.txt 文件。尤其是您通过 http 和 https 托管内容的时候,这些协议都需要有各自的 robots.txt 文件。例如,要让 Googlebot 只为所有的 http 网页而不为 https 网页编制索引,应使用下面的 robots.txt 文件。
对于 http 协议 (http://www.example.com/robots.txt):
User-agent: *
Allow: /
对于 https 协议 (https://www.example.com/robots.txt):
User-agent: *
Disallow: /
允许所有的漫游器访问您的网页
User-agent: *
Disallow:
(另一种方法: 建立一个空的 “/robots.txt” 文件, 或者不使用robot.txt。)
使用 robots.txt 文件拦截或删除网页
您可以使用 robots.txt 文件来阻止 Googlebot 抓取您网站上的网页。 例如,如果您正在手动创建 robots.txt 文件以阻止 Googlebot 抓取某一特定目录下(例如,private)的所有网页,可使用以下 robots.txt 条目:
User-agent: Googlebot
Disallow: /private
要阻止 Googlebot 抓取特定文件类型(例如,.gif)的所有文件,可使用以下 robots.txt 条目:
User-agent: Googlebot
Disallow: /*.gif$
要阻止 Googlebot 抓取所有包含 ? 的网址(具体地说,这种网址以您的域名开头,后接任意字符串,然后是问号,而后又是任意字符串),可使用以下条目:
User-agent: Googlebot
Disallow: /*?
尽管我们不抓取被 robots.txt 拦截的网页内容或为其编制索引,但如果我们在网络上的其他网页中发现这些内容,我们仍然会抓取其网址并编制索引。因此,网页网址及其他公开的信息,例如指 向该网站的链接中的定位文字,有可能会出现在 Google 搜索结果中。不过,您网页上的内容不会被抓取、编制索引和显示。
作为网站管理员工具的一部分,Google提供了robots.txt分析工具。它可以按照 Googlebot 读取 robots.txt 文件的相同方式读取该文件,并且可为 Google user-agents(如 Googlebot)提供结果。我们强烈建议您使用它。 在创建一个robots.txt文件之前,有必要考虑一下哪些内容可以被用户搜得到,而哪些则不应该被搜得到。 这样的话,通过合理地使用robots.txt, 搜索引擎在把用户带到您网站的同时,又能保证隐私信息不被收录。
误区一:我的网站上的所有文件都需要蜘蛛抓取,那我就没必要在添加robots.txt文件了。反正如果该文件不存在,所有的搜索蜘蛛将默认能够访问网站上所有没有被口令保护的页面。
每当用户试图访问某个不存在的URL时,服务器都会在日志中记录404错误(无法找到文件)。每当搜索蜘蛛来寻找并不存在的robots.txt文件时,服务器也将在日志中记录一条404错误,所以你应该做网站中添加一个robots.txt。
误区二:在robots.txt文件中设置所有的文件都可以被搜索蜘蛛抓取,这样可以增加网站的收录率。
网站中的程序脚本、样式表等文件即使被蜘蛛收录,也不会增加网站的收录率,还只会浪费服务器资源。因此必须在robots.txt文件里设置不要让搜索蜘蛛索引这些文件。
具体哪些文件需要排除, 在robots.txt使用技巧一文中有详细介绍。
误区三:搜索蜘蛛抓取网页太浪费服务器资源,在robots.txt文件设置所有的搜索蜘蛛都不能抓取全部的网页。
如果这样的话,会导致整个网站不能被搜索引擎收录。
robots.txt使用技巧
1. 每当用户试图访问某个不存在的URL时,服务器都会在日志中记录404错误(无法找到文件)。每当搜索蜘蛛来寻找并不存在的robots.txt文件时,服务器也将在日志中记录一条404错误,所以你应该在网站中添加一个robots.txt。
2. 网站管理员必须使蜘蛛程序远离某些服务器上的目录——保证服务器性能。比如:大多数网站服务器都有程序储存在“cgi-bin”目录下,因此在robots.txt文件中加入“Disallow: /cgi-bin”是个好主意,这样能够避免将所有程序文件被蜘蛛索引,可以节省服务器资源。一般网站中不需要蜘蛛抓取的文件有:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片等等。
下面是VeryCMS里的robots.txt文件:
User-agent: *
Disallow: /admin/ 后台管理文件
Disallow: /require/ 程序文件
Disallow: /attachment/ 附件
Disallow: /images/ 图片
Disallow: /data/ 数据库文件
Disallow: /template/ 模板文件
Disallow: /css/ 样式表文件
Disallow: /lang/ 编码文件
Disallow: /script/ 脚本文件
3. 如果你的网站是动态网页,并且你为这些动态网页创建了静态副本,以供搜索蜘蛛更容易抓取。那么你需要在robots.txt文件里设置避免动态网页被蜘蛛索引,以保证这些网页不会被视为含重复内容。
4. robots.txt文件里还可以直接包括在sitemap文件的链接。就像这样:
Sitemap: sitemap.xml
目前对此表示支持的搜索引擎公司有Google, Yahoo, Ask and MSN。而中文搜索引擎公司,显然不在这个圈子内。这样做的好处就是,站长不用到每个搜索引擎的站长工具或者相似的站长部分,去提交自己的sitemap文件,搜索引擎的蜘蛛自己就会抓取robots.txt文件,读取其中的sitemap路径,接着抓取其中相链接的网页。
5. 合理使用robots.txt文件还能避免访问时出错。比如,不能让搜索者直接进入购物车页面。因为没有理由使购物车被收录,所以你可以在robots.txt文件里设置来阻止搜索者直接进入购物车页面。
meta robots
如果要想URL完全不出现在搜索结果中,则需设置meta robots
<meta name="robots" content="onindex,nofollow">
上面代码表示:禁止所有搜索引擎索引本页,禁止跟踪本页上的链接。
当然还有其他类型的content,不过各个浏览器支持情况不同,所以这里忽略。
sitemap
站点地图格式分为HTML和XML两种。
HTML版本的是普通的HTML页面sitemap.html,用户可以直接访问,可以列出站点的所有主要链接,建议不超过100条。
XML版本的站点地图是google在2005年提出的,由XML标签组成,编码为utf-8,罗列页面所有的URL。其格式如下:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>//ke.qq.com</loc>
<lastmod>2015-12-28</lastmod>
<changefreq>always</changefreq>
<priority>1.0</priority>
</url>
...
</urlset>
其中urlset,url,loc三个为必须标签,lastmod,changefreq,priority为可选标签。
lastmod表示页面最后一次更新时间。
changefreq表示文件更新频率,有以下几种取值:always, hourly, daily, weekly, monthly, yearly, never。其中always表示一直变动,每次访问页面内容都不同;而never表示从来不变。
priority表示URL相对重要程度,取值范围为0.0-1.0,1.0表示最重要,一般用在网站首页,对应的0.0就是最不重要的,默认重要程度为0.5。(注意这里的重要度是我们标记的,并不代表搜索引擎真的就完全按照我们设置的重要度来排列)
sitemap.xml不能超过10M,而且每个sitemap文件中url的条数不要超过5万条,当你的sitemap文件很大的时候,可以分解为多个文件。如下分为两条,一条为基础,一条为产品详细页。
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap><loc>//ke.qq.com/sitemap-basic.xml</loc><lastmod>2015-12-28T02:10Z</lastmod></sitemap>
<sitemap><loc>//ke.qq.com/sitemap-product.xml</loc><lastmod>2015-12-28T02:10Z</lastmod></sitemap>
</sitemapindex>
SEO工具
- 百度搜索风云榜
- 百度指数
- 百度站长平台
- meta seo inspector,检查标签的,谷歌插件
- seo in china,百度收录的各种数据,谷歌插件
- check my links,检查链接,谷歌插件
- seo quake,统计各种数据,谷歌插件